

利用R语言heatmap.2函数进行聚类并画热图

数据聚类然后展示聚类热图是生物信息中组学数据分析的常用方法,在R语言中有很多函数可以实现,譬如heatmap,kmeans等,除此外还有一个用得比较多的就是heatmap.2。最近在网上看到一个笔记文章关于《一步一步学heatmap.2函数》,在此与大家分享。由于原作者不详,暂未标记来源,请原作者前来认领哦,O(∩_∩)O哈哈~
数据如下:
1 2 3 4 5 | library(gplots) data(mtcars) x <- as.matrix(mtcars) rc <- rainbow(nrow(x), start=0, end=.3) cc <- rainbow(ncol(x), start=0, end=.3) |

X就是一个矩阵,里面是我们需要画热图的数据。
Rc是一个调色板,有32个颜色,渐进的
Cc也是一个调色板,有11个颜色,也是渐进的
首先画一个默认的图:
1 | heatmap.2(x) |
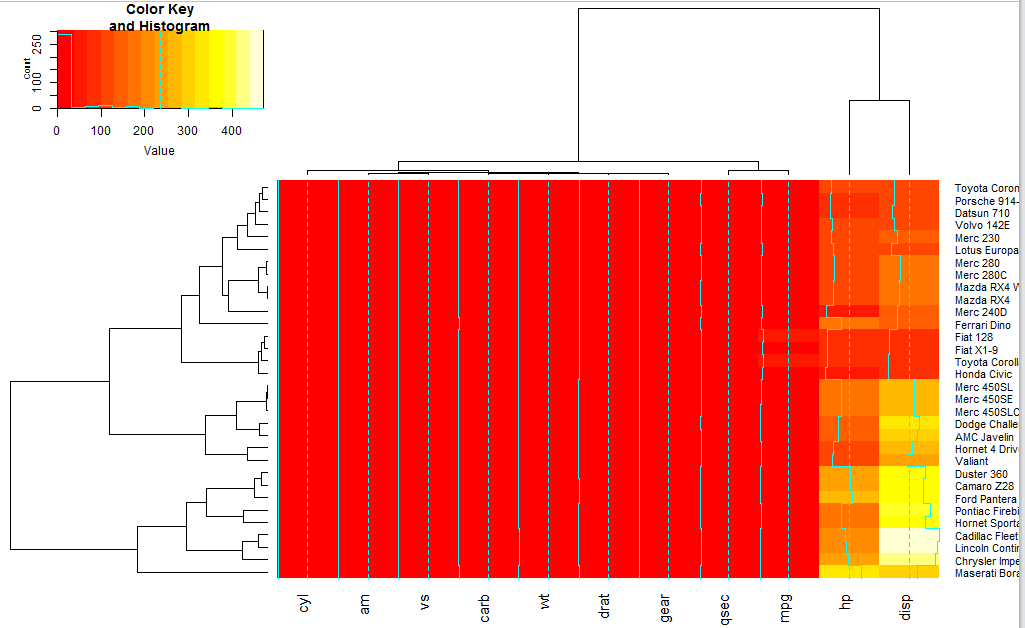
然后可以把聚类数可以去掉:就是控制这个dendrogram参数
1 | heatmap.2(x, dendrogram="none") |

然后我们控制一下聚类树
1 2 | heatmap.2(x, dendrogram="row") # 只显示行向量的聚类情况 heatmap.2(x, dendrogram="col") #只显示列向量的聚类情况 |
下面还是在调控聚类树,但是我没看懂跟上面的参数有啥子区别!
1 2 3 4 | heatmap.2(x, keysize=2) ## default - dendrogram plotted and reordering done. heatmap.2(x, Rowv=FALSE, dendrogram="both") ## generate warning! heatmap.2(x, Rowv=NULL, dendrogram="both") ## generate warning! heatmap.2(x, Colv=FALSE, dendrogram="both") ## generate warning! |
接下来我们可以调控行列向量的label的字体大小方向
首先我们调控列向量,也就是x轴的label
1 2 3 4 5 6 7 8 9 | heatmap.2(x, srtCol=NULL) heatmap.2(x, srtCol=0, adjCol = c(0.5,1) ) heatmap.2(x, srtCol=45, adjCol = c(1,1) ) heatmap.2(x, srtCol=135, adjCol = c(1,0) ) heatmap.2(x, srtCol=180, adjCol = c(0.5,0) ) heatmap.2(x, srtCol=225, adjCol = c(0,0) ) ## not very useful heatmap.2(x, srtCol=270, adjCol = c(0,0.5) ) heatmap.2(x, srtCol=315, adjCol = c(0,1) ) heatmap.2(x, srtCol=360, adjCol = c(0.5,1) ) |
然后我们调控一下行向量,也就是y轴的label
1 2 3 | heatmap.2(x, srtRow=45, adjRow=c(0, 1) ) heatmap.2(x, srtRow=45, adjRow=c(0, 1), srtCol=45, adjCol=c(1,1) ) heatmap.2(x, srtRow=45, adjRow=c(0, 1), srtCol=270, adjCol=c(0,0.5) ) |
设置 offsetRow/offsetCol 可以把label跟热图隔开!
1 2 3 4 5 6 7 8 9 | ## Show effect of offsetRow/offsetCol (only works when srtRow/srtCol is ## not also present) heatmap.2(x, offsetRow=0, offsetCol=0) heatmap.2(x, offsetRow=1, offsetCol=1) heatmap.2(x, offsetRow=2, offsetCol=2) heatmap.2(x, offsetRow=-1, offsetCol=-1) heatmap.2(x, srtRow=0, srtCol=90, offsetRow=0, offsetCol=0) heatmap.2(x, srtRow=0, srtCol=90, offsetRow=1, offsetCol=1) heatmap.2(x, srtRow=0, srtCol=90, offsetRow=2, offsetCol=2) heatmap.2(x, srtRow=0, srtCol=90, offsetRow=-1, offsetCol=-1) |
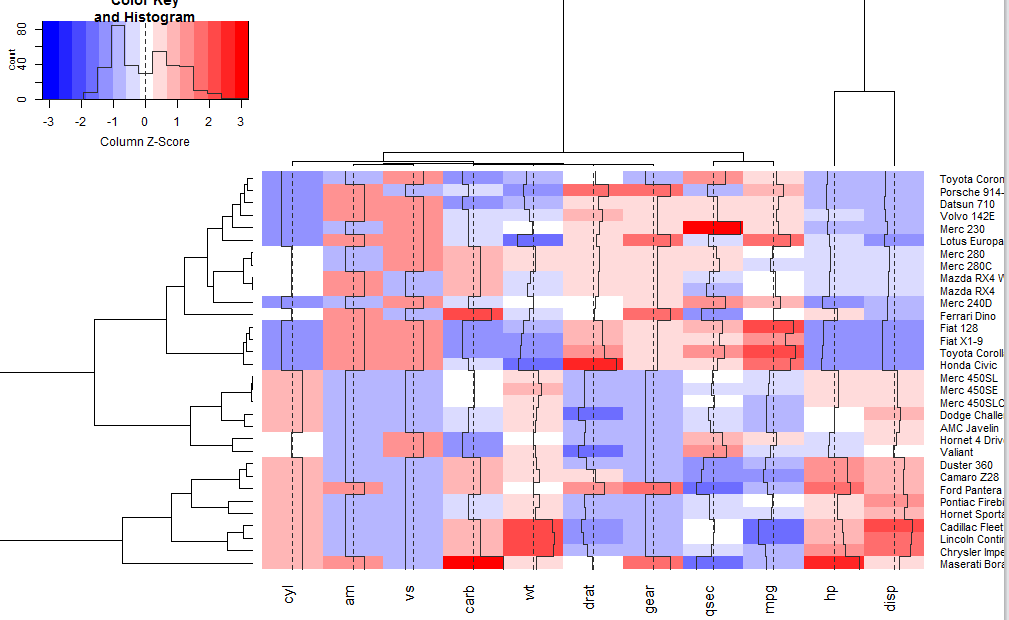
1 2 | ## Show effect of z-score scaling within columns, blue-red color scale hv <- heatmap.2(x, col=bluered, scale="column", tracecol="#303030") |
hv是一个热图对象!!!
1 2 | > names(hv) # 可以看到hv对象里面有很多子对象 > "rowInd" "colInd" "call" "colMeans" "colSDs" "carpet" "rowDendrogram" "colDendrogram" "breaks" "col" "vline" "colorTable" ## Show the mapping of z-score values to color bins hv$colorTable |
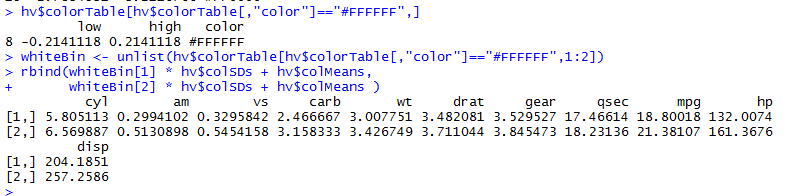
1 2 | ## Extract the range associated with white 我们得到了热图的颜色的数值映射矩阵,接下来就可以进行一系列的操作~!!! hv$colorTable[hv$colorTable[,"color"]=="#FFFFFF",] |

首先得到了白色所对应的数值区间!
然后还可以通过一下命令,直接求出属于白色区间的那些数值。
1 2 | whiteBin <- unlist(hv$colorTable[hv$colorTable[,"color"]=="#FFFFFF",1:2]) rbind(whiteBin[1] * hv$colSDs + hv$colMeans, whiteBin[2] * hv$colSDs + hv$colMeans ) |
调整scale参数选择按照列还是行来进行数据的标准化
1 | heatmap.2(x, col=bluered, scale="column", tracecol="#303030") |
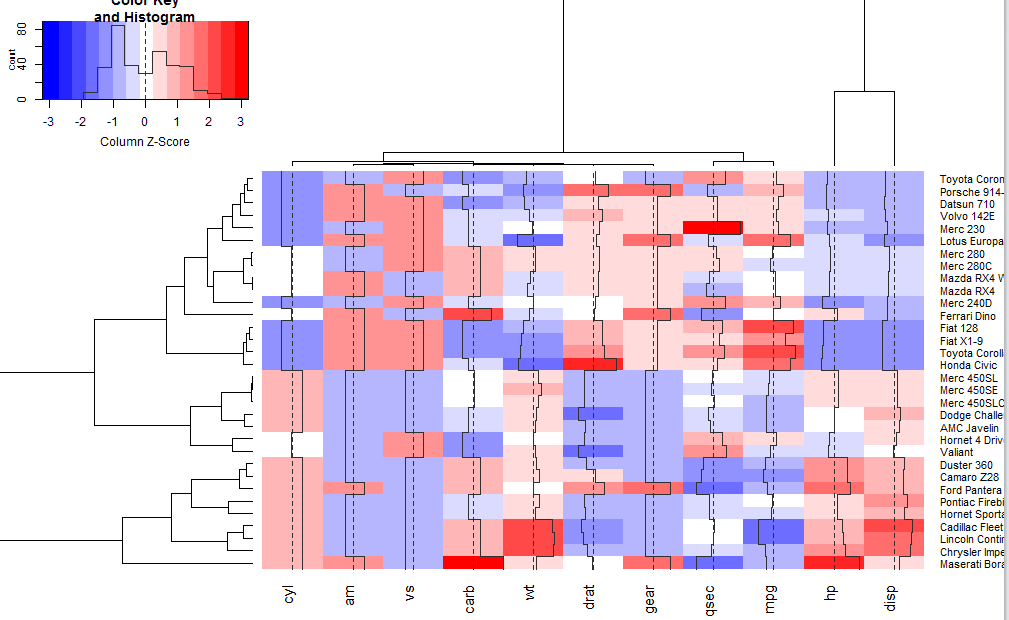
1 | heatmap.2(x, col=bluered, scale="row", tracecol="#303030") |
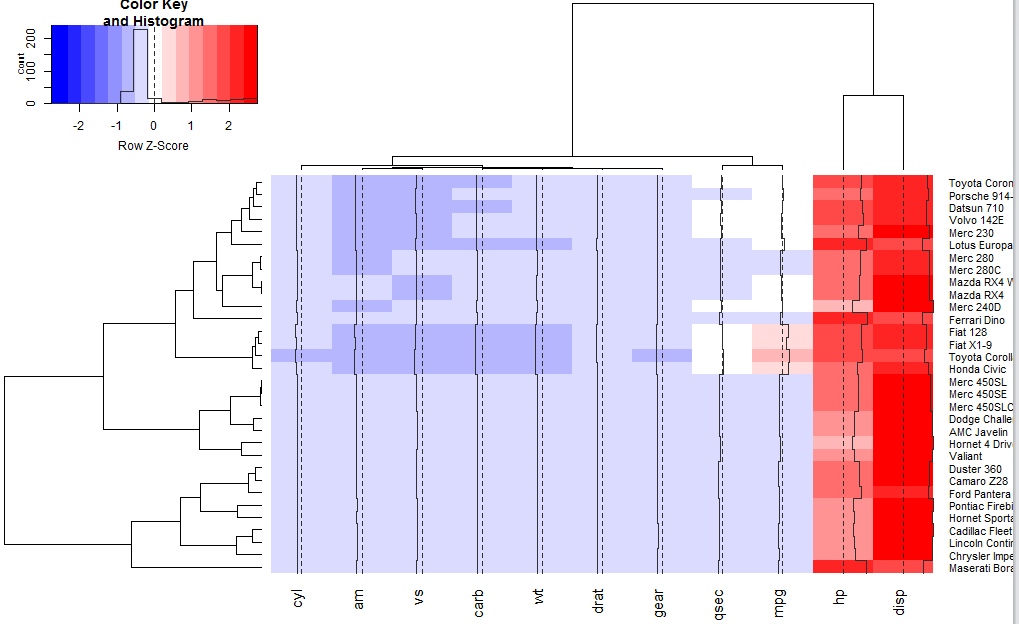
如果选择了标准化,那么还可以手工调整标准化的参数:
rowMeans, rowSDs
mean and standard deviation of each row: only present if scale="row"
colMeans, colSDs
mean and standard deviation of each column: only present if scale="column"
通过hclustfun参数来调整聚类方法:参考:怎样在heatmap中使用多种cluster方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | Cluster_Method<-c( "ward", "single", "complete", "average", "mcquitty", "median", "centroid") #R语言里面自带的hclust函数共有7种聚类方法 for (i in 1:length(Cluster_Method)){ #make a function to extract the cluster method myclust<-function(x){ hclust(x,method=Cluster_Method[i]) } #make heatmap by jpeg jpeg(filename=paste(Cluster_Method[i],'.jpg'),width=1024,height=728) heatmap.2(as.matrix(Data_Top1k_Var), trace='none', hclustfun=myclust, labRow=NA, ColSideColors=c('black',grey(0.4),'lightgrey')[as.factor(CellLine_Anno$Type)], xlab='CellLines', ylab='Probes', main=Cluster_Method[i], col=greenred(64)) dev.off() } |
这样就可以一下子把七种cluster的方法依次用到heatmap上面来。而且通过对cluster树的比较,我们可以从中挑选出最好、最稳定到cluster方法,为后续分析打好基础!
对下面这个数据聚类:

1 2 3 | require(graphics) hc <- hclust(dist(USArrests), "ave") plot(hc) |
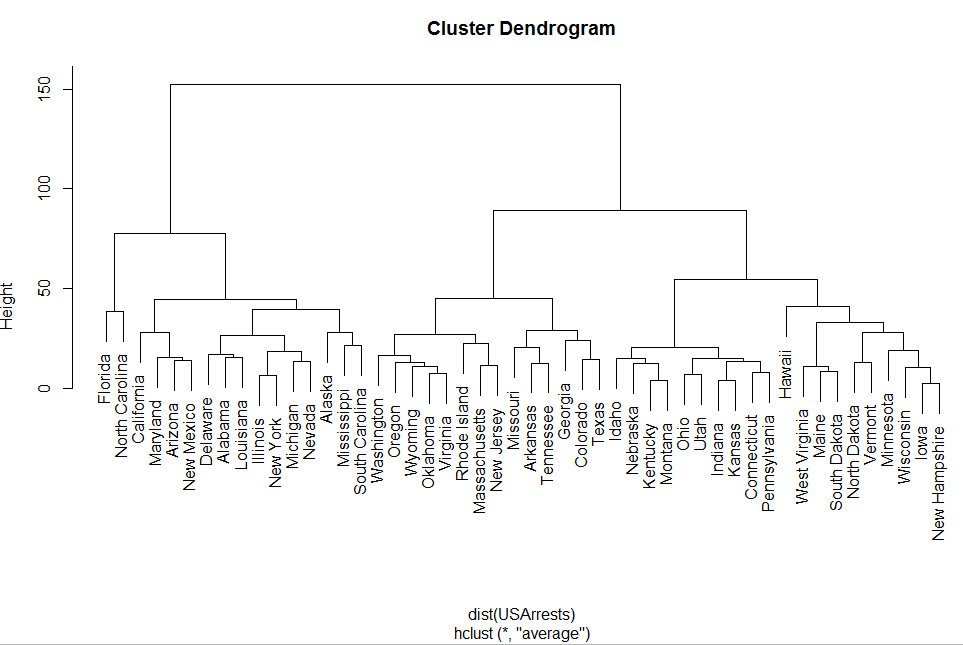
首先对一个数据框用dist函数处理得到一个dist对象!

Dist对象比较特殊,专门为hclust函数来画聚类树的!

相关推荐:
- NCBI在线BLAST使用方法与结果详解 2966
- 神经网络术语:Epoch、Batch Size和迭代 530
- Consed的安装与使用教程 479
- WGCNA分析使用教程 288
- 陈连福的NGS生物信息学培训教材V2.1 279



最新创建圈子
-
 原料药研发及国内外注册申报
原料药研发及国内外注册申报
2019-01-25 10:41圈主:caolianhui 帖子:33 -
 制药工程交流
制药工程交流
2019-01-25 10:40圈主:polysciences 帖子:30 -
 健康管理
健康管理
2019-01-25 10:40圈主:neuromics 帖子:20 -
 发酵技术
发酵技术
2019-01-25 10:39圈主:fitzgerald 帖子:17 -
 医学肿瘤学临床试验
医学肿瘤学临床试验
2019-01-25 10:39圈主:bma 帖子:58






heatmap.2(x, dendrogram=”none”)Error in .External.graphics(C_layout, num.rows, num.cols, mat, as.integer(num.figures), : invalid graphics state这个是怎么回事?